

Introduction
Industrial system manufacturers and engineering solution providers rely on large, complex technical manuals to support commissioning, operation, and maintenance in the field. These documents are often hundreds of pages long, updated frequently, and reused across multiple product variants and configurations. Navigating this volume of information manually is a significant operational bottleneck, often leading to prolonged repair times, increased field error rates, and costly equipment downtime. This creates a strong need for AI systems that can reliably extract accurate information from these manuals.
Large Language Models (LLMs) have become powerful engines for document understanding and question answering. However, they are constrained by a fundamental architectural limit: the context window. Even though recent models support longer contexts, research such as Chroma’s context rot study has shown that model performance deteriorates as context length grows. This makes it challenging for LLMs to accurately interpret and reason over long, domain-specific documents such as complex, multi-hundred-page installation and maintenance guides.
To mitigate this limitation, Retrieval Augmented Generation (RAG) has emerged as the dominant solution. Instead of passing the entire document into the model, RAG retrieves and feeds only the most relevant text chunks based on the user’s query, thereby optimizing the effective context length. However, conventional vector-based RAG methods depend heavily on static semantic similarity and face several key limitations.
The Limitations of Vector-based RAG
Vector-based RAG relies on semantic embeddings and vector databases to identify relevant text chunks. In the preprocessing stage, the document is first split into smaller chunks, then each chunk is embedded into a vector space using an embedding model, and the resulting vectors are stored in a vector database (such as Chroma or Pinecone). During the query stage, the user query is embedded using the same embedding model, the vector database is searched for semantically similar chunks, and the system retrieves the top-k results, which are then used to form the model’s input context.
While simple and effective for short texts, vector-based RAG is fundamentally limited when applied to long, complex documents such as technical manuals. Specifically, it faces the following challenges:
- Lack of Reasoning. Vector-based RAG systems retrieve text based on static semantic similarity matches. They cannot understand procedural order or multi-hop causal relationships.
- Chunking Breaks the Semantic Integrity. Documents are split into fixed-size chunks (e.g., 512 or 1000 tokens) for embedding. This “hard chunking” often cuts through sentences, paragraphs, or sections, fragmenting context.
- Missing Information Caused by Low Recall. Vector retrieval assumes that the most semantically similar text to the query is also the most relevant. This is especially problematic in technical documents, where many passages share near-identical semantics but differ in relevance, so the truly relevant section is often not retrieved, resulting in low recall.
- Context Confusion Caused by Low Precision. Because many semantically similar passages are retrieved together, the LLM receives redundant or even inconsistent chunks whose instructions or conditions do not fully align, which leads to noisy and sometimes incorrect answers.
To address these challenges, we introduce PageIndex, a vectorless, reasoning-based retrieval framework.
PageIndex: Vectorless Reasoning-based Retrieval
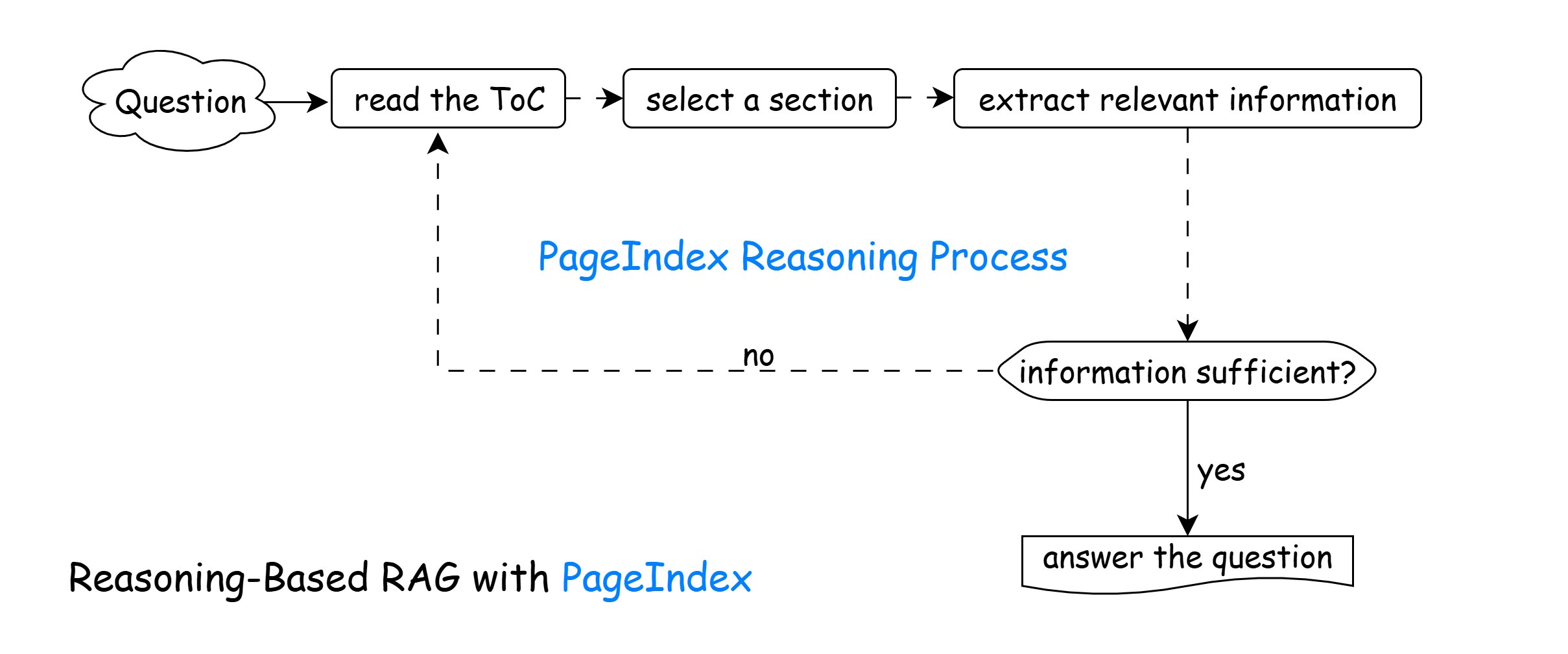
PageIndex's Vectorless Reasoning-based RAG mimics how humans naturally navigate and extract information from long documents. Unlike traditional vector-based methods that rely on static semantic similarity, this approach uses a dynamic, iterative reasoning process to actively decide where to look next based on the evolving context of the question.
It follows the iterative process below:
- Read the Table of Contents (ToC). Understand the document's structure and identify sections that might be relevant.
- Select a Section. Choose the section most likely to contain useful information based on the question.
- Extract Relevant Information. Parse the selected section to gather any content that could help answer the question.
- Is the Information Sufficient?
- Yes → Proceed to Answer the Question.
- No → Return to Step 1 and repeat the loop with another section.
- Answer the Question. Once enough information is collected, generate a complete and well-supported answer.
We describe this framework in detail in PageIndex: Next-Generation Vectorless, Reasoning-based RAG.
In the next section, we show how this framework directly addresses the practical limitations of vector-based RAG on real-world technical manuals.
Overcoming Vector-based RAG Limitations in Technical Manuals
Industrial technical manuals, such as multi-hundred-page chiller, HVAC, PLC, or drive system guides, are especially challenging for retrieval systems. They contain repeated, semantically similar terminology, multi-step procedures, and dense cross-references. These characteristics expose structural weaknesses in traditional vector-based RAG pipelines and can lead to incorrect answers.
In this section, we analyze four specific fundamental limitations of vector-based RAG. We use side-by-side Q&A examples to illustrate why vector-based methods inherently fail in performing accurate question answering over long, complex technical manuals, and how PageIndex’s reasoning framework overcomes these structural limitations.
For our comparison:
-
Vector-based RAG: We use Google’s Gemini File Search RAG API with Gemini 3 Pro, as demonstrated in the official Ask the Manual app. It represents a standard, production-grade vector RAG implementation.
-
Reasoning-based RAG: We use PageIndex Chat, powered by PageIndex's reasoning-based indexing and retrieval techniques.
To ground the comparison in a realistic setting, the example questions are practical queries that field engineers routinely ask over three real-world technical manuals from a global leader in manufacturing.
1. Lack of Reasoning
Vector-based RAG relies on static semantic similarity and cannot perform multi-hop reasoning. It matches text that looks similar to the user’s query, but it does not follow the underlying logic of a procedure or troubleshooting path. As a result, it often retrieves only a piece of information (for example, a single step or paragraph) while missing other sections that are logically required to answer the question completely, such as related warnings, prerequisites, dependencies, or follow-on checks.
PageIndex, by contrast, treats retrieval as a dynamic reasoning process. It interprets the content of the retrieved section to identify logical gaps (such as referenced warnings or prerequisites) and actively decides where to look next to fill them. It then jumps to those related sections to assemble a coherent answer.
Example Q&A
Q: "How do I change the dehydrator and what safety precautions apply?"
What the correct answer must include:
- The dehydrator replacement procedure (Page 29), and
- The safety precautions required by the hazards implied in that procedure (including refrigerant-related warnings on Page 6).
❌ Google's Ask the Manual (vector-based RAG)
It retrieved the mechanical procedure on Page 29 but missed the critical "Refrigerant warning" on Page 6.
- Why it failed (Static, Single-Hop Retrieval): Since the system performed only a single retrieval based on direct keyword matches, it found the dehydrator replacement procedure and some of the warnings but stopped there. It lacked the reasoning required to perform a second "hop" — connecting the dehydrator to its working fluid (refrigerant) and subsequently retrieving the refrigerant warning associated with that fluid.
✅ PageIndex (reasoning-based RAG)
It correctly retrieved both the procedure (Page 29) AND the "Refrigerant warning" (Page 6).
- Why it succeeded (Structure-Aware Reasoning): PageIndex finds the dehydrator procedure on Page 29 and sees Step 4 mention "refrigerant leaks"; it then infers that refrigerant safety guidance is relevant. It then follows the document structure to the safety pages and pulls in the "Refrigerant warning" on Page 6.
2. Chunking Breaks the Semantic Integrity
Vector-based RAG relies on fixed-size chunking. These chunks rarely line up with natural units such as procedures, checklists, figures, or cross-referenced instructions in the technical manuals. When one logical unit is split across multiple chunks, a vector-based RAG system processes each fragment independently and often retrieves only a fragment instead of the complete procedure, causing loss of meaning and context. As a result, critical steps, lists, diagrams, and notes that belong together become separated, and the model cannot reliably reconstruct the full intent.
PageIndex does not rely on any chunking strategies or vector databases. Instead, it navigates the document structure and retrieves content by its natural logical boundaries, such as full sections or subsections. This ensures that procedures, checklists, and their relevant context remain intact, allowing the model to process complete, coherent units of information.
Example Q&A
Q: "Where is the list of what the installer is required to inspect before lifting, and where are the lug locations shown in the figures?"
What the correct answer must include:
- The 5-point inspection list on Page 20 (Ropes, Chains, Hooks, Safety Latch, Drum Spooling).
- The lug locations shown across Figures 5–12.
❌ Google's Ask the Manual (vector-based RAG)
Failure 1 (The Checklist): It does not point to the checklist on Page 20. Instead it paraphrases the responsibility bullets from Page 19 ("inspection and operation of the lifting equipment," etc.), which are a different list and not the "At a minimum, the installer must check…" checklist the question is asking about.
- Why it failed (Chunk Isolation): The retrieved chunk ends right at "At a minimum, the installer must…," while the actual checklist items are in the next chunk. Because chunks are processed independently, the model never sees the list that follows.
Failure 2 (The Lug Locations): It identified Figures 8–12 but omitted Figures 5–7.
- Why it failed (Semantic Over-weighting): The chunks containing Figures 8–12 happened to be dense with keywords like "lifting point" and "rigging." The chunks for Figures 5–7 used different phrasing (e.g., "tube sheet holes"). The vector search ranked the high-keyword chunks (8-12) as relevant and discarded the others (5-7), resulting in an incomplete answer.
✅ PageIndex (reasoning-based RAG)
Success 1 (The Checklist): It correctly identifies where the installer's inspection checklist is: Page 20, and reproduces the items on that list accurately.
- Why it succeeded (No Chunking Strategies / Structural Awareness): By operating at the document-structure level (section → page → figures), it keeps together the checklist content and the associated rigging instructions instead of treating them as isolated chunks.
Success 2 (The Lug Locations): It correctly stated that lug locations are shown in Figures 5–12.
- Why it succeeded (Reasoning over Reference): PageIndex analyzed the retrieved text and found the specific directive: "Attach the chains... as shown in Figures 5–12." This explicit reference allowed it to capture the full range of figures (including 5, 6, and 7) based on the instruction, rather than relying on whether each individual figure caption contained the word semantically similar to "lug."
3. Missing Information Caused by Low Recall
In highly technical manuals, many terms and phrases may appear semantically similar yet refer to very different mechanisms, conditions, or subsystems. As a result, with a fixed top-K retrieval limit and single one-hop retrieval, vector search can return passages that sound similar to the query while failing to retrieve chunks that are truly relevant, thereby missing key information.
PageIndex overcomes this by using an iterative reasoning process. Rather than grabbing the top matches and immediately attempting an answer, it actively evaluates whether the retrieved information is sufficient to address the user's specific intent. The system only generates a response once it assesses that the collected information is complete, ensuring high recall.
Example Q&A
Q: "Why would high ambient cause the unit to enter mechanical mode?"
What the correct answer must include: The answer should explain the Control Logic mechanism on Page 142.
❌ Google's Ask the Manual (vector-based RAG)
It describes high-ambient protection faults, not the mechanical-mode transition mechanism the query is asking.
- Why it failed (Semantic embedding mismatch): The query contains the phrase "high ambient." In vector-based RAG systems, this phrase is strongly semantically similar to "High Ambient Temperature Faults" and "Safety Cutouts." The system retrieved those high-ranking chunks and ignored the "Free Cooling Control" section, where the "ambient" reference was less frequent but relevant.
✅ PageIndex (reasoning-based RAG)
It correctly explains the mechanism: High ambient causes free cooling to become ineffective → valve closes → system goes to mechanical mode.
- Why it succeeded (Iterative Reasoning / Structure-Awareness): Instead of getting trapped by the high-ranking keywords associated with "High Ambient Temperature Faults," PageIndex first analyzed the document structure to target the specific "Operating Modes" section (pages 139–142). It then correctly synthesized the multi-step control logic, identifying that high ambient temperature forces the free cooling valve to close, which is the specific condition that triggers the system's transition into Mechanical Cooling Mode. It also checked for "unit faults" and "cutout settings" on Pages 135-139, and 178-179 to validate the context, allowing it to correctly prioritize the operational mode transition over a safety shutdown explanation.
Additional Evidence from Question 2:
This limitation was also observed in the previous "Lug Locations" example (Failure 2 and Success 2).
- Google Ask the Manual Failure: It missed Figures 5–7 because the text around them described "tube sheets" rather than repeating the specific keyword "lifting lug."
- PageIndex Success: By reading the full context ("...as shown in Figures 5-12"), PageIndex understood that Figures 5, 6, and 7 were relevant.
4. Context Confusion Caused by Low Precision
Vector-based RAG relies on semantic similarity. In technical manuals, however, many distinct procedures share near-identical terminology (e.g., "pump alignment" for different models). Consequently, vector search often retrieves a mix of redundant and irrelevant chunks that sound alike. The LLM then has to reason over this noisy, overly broad context, which makes it easy to mix together details that don’t actually belong, leading to confident but wrong answers.
PageIndex navigates the document structure to locate the specific section that answers the user's question, mimicking the workflow of a human expert. Because it targets content based on logic rather than chunk similarity, it inherently avoids retrieving material that is semantically similar but unrelated.
Example Q&A
Q: "When is glycol pumping required in closed-loop free cooling?"
What the correct answer must include: The answer should accurately reflect the Closed-Loop configuration (Page 20-21).
❌ Google's Ask the Manual (vector-based RAG)
It falsely treats the free-cooling valve as part of the closed-loop system, and falsely states that glycol pumping is required during initial charging/topping up of the closed loop, even though the manual explicitly says the valve only exists in the open-loop system and never describes using the built-in free-cooling glycol pump for charging.
- Why it failed (Context Confusion from Redundant Retrievals): It pulls in passages about both open-loop (with a free-cooling valve) and closed-loop (with a glycol pump) because they share terms like "free cooling", "valve", "glycol", and "flow". With these mixed together, the LLM merges details from different configurations and fills in missing pieces with plausible guesses, so it wrongly assigns the valve to the closed-loop system and invents a charging role for the glycol pump that the manual does not support.
✅ PageIndex (reasoning-based RAG)
It correctly states that the glycol pump is only present in closed-loop systems, not open-loop – this matches the manual. Also it correctly states that the glycol pump circulates glycol through the free-cooling coil and then to the BPHX to absorb heat from the chilled water.
- Why it succeeded (Structure-Aware Reasoning): Instead of mixing in open-loop content, it uses the document structure to locate only the section that is actually about the closed-loop system. It naturally excluded the "Open-Loop" content that confused the vector model. It then connected the specific logical points without cross-contaminating the data with irrelevant valve operations.
Summary: Vector vs. Reasoning-based RAG
| Limitations | Vector-based RAG | Reasoning-based RAG (PageIndex) |
|---|---|---|
| Lack of Reasoning | Performs only static similarity search and cannot follow procedural order or multi-hop logic. | Treats retrieval as a dynamic reasoning process; interprets content to actively decide where to look next. |
| Chunking Breaks Semantic and Contextual Integrity | Hard chunking cuts through sentences, lists, and steps, so related context is separated and fragmented. | Avoids breaking documents into artificial chunks, preserving the full hierarchical and semantic structure of the document for better context retention and structure-aware retrieval. |
| Missing Information Caused by Low Recall | Often misses relevant sections that use different terminology or lack strong semantic overlap. | Uses iterative reasoning to assess whether information is sufficient, ensuring high recall by gathering all necessary details before answering. |
| Context Confusion Caused by Low Precision | Retrieves redundant or irrelevant chunks that sound similar, leading to mixed contexts and hallucinations. | Navigates to the specific relevant section based on logic, avoiding "look-alike" noise and ensuring a focused context. |
Conclusion
Vector-based RAG searches for similar text, whereas PageIndex’s agentic, reasoning-based RAG actively decides where to look and why. By combining structured document representations with iterative reasoning, PageIndex enables LLMs to navigate technical manuals with the logic of a field engineer. For manufacturers, this marks the shift from simple search engines to true intelligent document understanding — systems that deliver reliable, context-aware answers aligned with real operational workflows.