

Introduction
In modern document question answering (QA) systems, Optical Character Recognition (OCR) serves an important role by converting PDF pages into text that can be processed by Large Language Models (LLMs). The resulting text can provide contextual input that enables LLMs to perform question answering over document content.
Traditional OCR systems typically use a two-stage process that first detects the layout of a PDF — dividing it into text, tables, and images — and then recognizes and converts these elements into plain text. With the rise of vision-language models (VLMs) (such as Qwen-VL and GPT-4.1), new end-to-end OCR models like DeepSeek-OCR have emerged. These models jointly understand visual and textual information, enabling direct interpretation of PDFs without an explicit layout detection step.
However, this paradigm shift raises an important question:
If a VLM can already process both the document images and the query to produce an answer directly, do we still need the intermediate OCR step?
In this blog post, we examine the inherent limitations of the current OCR pipeline from an information-theoretic perspective and discuss why a direct, vision-based approach can be more effective. We also demonstrate a practical implementation of a vision-based question-answering system for long documents, powered by PageIndex and GPT-4.1.
The code is available in our GitHub repo.
Limitations of OCR-based QA Pipeline
A typical OCR-based QA system follows the following process:

Despite the widespread adoption of this approach, it faces a fundamental limitation that ultimately constrains its performance:
Converting a 2D visual document into a 1D text sequence inevitably discards spatial, contextual, and sometimes semantic relationships.While structure-rich text formats such as Markdown or HTML can preserve some layout information, they fall short in representing complex documents — such as large tables with merged cells or embedded figures.
Therefore, the 1D representation produced by OCR is inherently lossy. In such a representation, downstream tasks may depend on precisely the information that has been lost, thereby capping the upper-bound performance of any OCR-based pipelines.From an information-theoretic perspective, the OCR step is a non-invertible operation, which may reduce the mutual information of the input document and the final answer — a consequence of the information processing inequality. Thus, rather than striving for perfect text extraction, we should reconsider the document QA task from first principles: if the ultimate goal is to answer questions about visual content, why not reason directly over the image itself?
Information-Preserving QA Systems without OCR
Rather than translating visual information into an intermediate text format which will inevitably lose information, we can design an end-to-end VLM-based pipeline that processes images directly and generates answers:
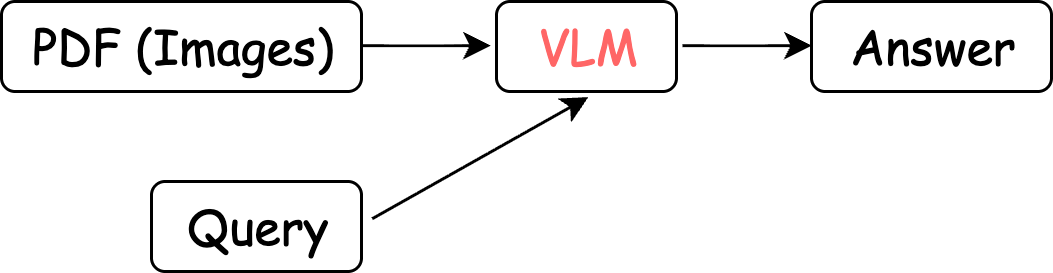
This simplified process preserves information throughout the entire QA lifecycle and more closely mimics how humans naturally read and perform question answering on documents. When we read a document to find an answer, we don't start by converting a page into plain text — instead, we perceive the page as an integrated whole, combining visual cues, layout comprehension, and semantic reasoning simultaneously rather than in isolated steps.
The Challenges of Scaling to Long Documents
In the previous discussion, we implicitly assumed an ideal scenario in which a VLM can process an arbitrary number of PDF pages. In practice, however, real-world documents often span hundreds of pages — quickly exceeding the model's context window.Recent studies such as DeepSeek-OCR and Glyph demonstrate that vision-based document understanding can achieve strong token efficiency. However, for documents spanning hundreds of pages, model performance tends to degrade with longer token sequences — a phenomenon known as context rot. This limitation also affects VLMs, as illustrated in Figure 5 of Glyph’s report. To handle long documents effectively, we must retrieve and feed into the VLM only the most relevant pages.
In a classic OCR-based pipeline, there are many existing tools for retrieving information from large volumes of text — for example, embedding-based retrieval methods that identify semantically similar passages. Although image-embedding models exist, they are typically trained on natural images rather than documents, making them far less effective for image-based retrieval of document content.
Even text-based embeddings have well-known limitations: they often capture surface-level similarity instead of true relevance, performing poorly on domain-specific, lengthy documents where terminology is highly repetitive or semantically similar.A comprehensive investigation on practical embedding-based retrieval limitations can be found in this blog post. Likewise, image-based embedding models for document retrieval face comparable challenges.
These retrieval limitations give rise to a new challenge:
Can we design retrieval methods that work natively with vision-based QA systems for long documents?
In the next section, we introduce a vectorless indexing approach that is naturally compatible with VLM-based document QA systems and scales gracefully to large and complex documents.
Page Selection with PageIndex
Let us recall how a human decides which page to read in a long document. Typically, we first look at the table of contents (ToC) to identify which section or page might be relevant, and then turn to that page for a closer read.
PageIndex mimics this human behavior: it generates an LLM-friendly “ToC” that the model can directly reason over. Once the LLM identifies the target page, the image of that page is sent to the VLM for processing. This procedure repeats until sufficient knowledge has been gathered to answer the query. The complete PageIndex reasoning process is illustrated below:
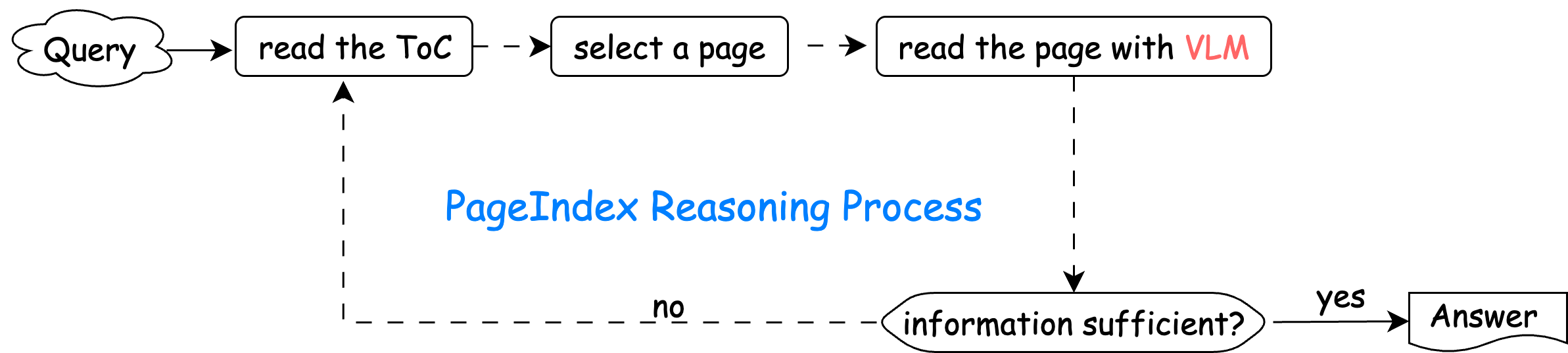
In this workflow, the “ToC” generated by PageIndex acts as an in-context indexA detailed explanation of how to design such an LLM-friendly ToC index can be found in this blog post. for the document.
In our GitHub notebook, we demonstrate how this concept works in practice through a vision-based, information-preserving QA pipeline. In this setup, PageIndex serves as a reasoning-based retrieval layer that determines which pages to read, while GPT-4.1 operates as the VLM that handles multimodal reasoning and produces the final answers.
Instead of converting PDF pages into text via OCR, each page is processed directly as an image. PageIndex navigates the document’s hierarchical structure to identify the most relevant pages, which are then passed to the vision-language model for detailed visual understanding and response generation. This architecture preserves the document’s spatial layout, contextual relationships, and visual semantics — information that would otherwise inevitably be lost in text-only pipelines.
By combining PageIndex's vectorless retrieval with VLM's multimodal reasoning, the system demonstrates how long-document understanding can be achieved without OCR or embeddings, aligning closely with how humans naturally read, navigate, and reason over complex documents.
Conclusion
Although the OCR step has fundamental limitations within the pipeline of document QA systems, it remains useful when the document’s information is primarily contained in 1D text sequences or when downstream tasks do not rely on spatial or visual context.In addition to its use as a pipeline preprocessing tool, the OCR task itself can serve as an effective auxiliary regularizer during the training or fine-tuning of vision-language models (VLMs) to prevent overfitting and improve generalization; see Glyph’s report for an example. However, for documents with complex layouts, visual hierarchies, or embedded images, an overly complex OCR pipeline may not be ideal. In such cases, a VLM-based approach, paired with an appropriate indexing and retrieval strategy such as PageIndex, could emerge as a strong candidate for the default solution in future document intelligence systems.