
The Rise of Agentic Retrieval Over Vector Indexing
The successful stories of Claude Code have shown that in RAG, you can skip heavyweight vector databases and let the LLM itself handle retrieval using simple tools, such as well-written llms.txt and grep calls. Surprisingly, this minimalist approach delivers more accurate and faster retrieval, demonstrating that reasoning-driven retrieval can outperform embedding-based methods in both retrieval precision and latency. This insight challenges the default assumptions behind mainstream RAG systems.
We take the same principle beyond code.
PageIndex (GitHub) is a vectorless, reasoning-based RAG framework that mirrors how human experts read, navigate, and extract knowledge from long, complex documents. Instead of relying on chunking and vector similarity search, PageIndex transforms documents into a tree-structured, in-context index and enables LLMs to perform agentic reasoning over that structure for context-aware retrieval. The retrieval process is traceable and interpretable, and requires no vector database or chunking.
For more details, see the blog post on the PageIndex framework.
The RAG Pipeline We All Know, but Increasingly Use Less
Classic RAG Pipelines
The classic RAG pipeline works like this:
split content into chunks → embed → store in a vector DB → semantic search → (blend with keyword search) → (rerank) → stuff the context → answer.
It works, but it’s complex to build, hard to maintain, and slow to iterate, often more infrastructure than you really need.
Agentic Retrieval is Emerging
In contrast, a new wave of coding agents like Claude Code takes a refreshingly simple approach:
- No pre-indexing.
- Just agentic retrieval: give the LLM a few basic file tools (grep, glob, etc.) and a compact directory of the space (e.g., a curated llms.txt describing what’s where).
- Let the model decide what to open next based on its own thinking and reasoning.
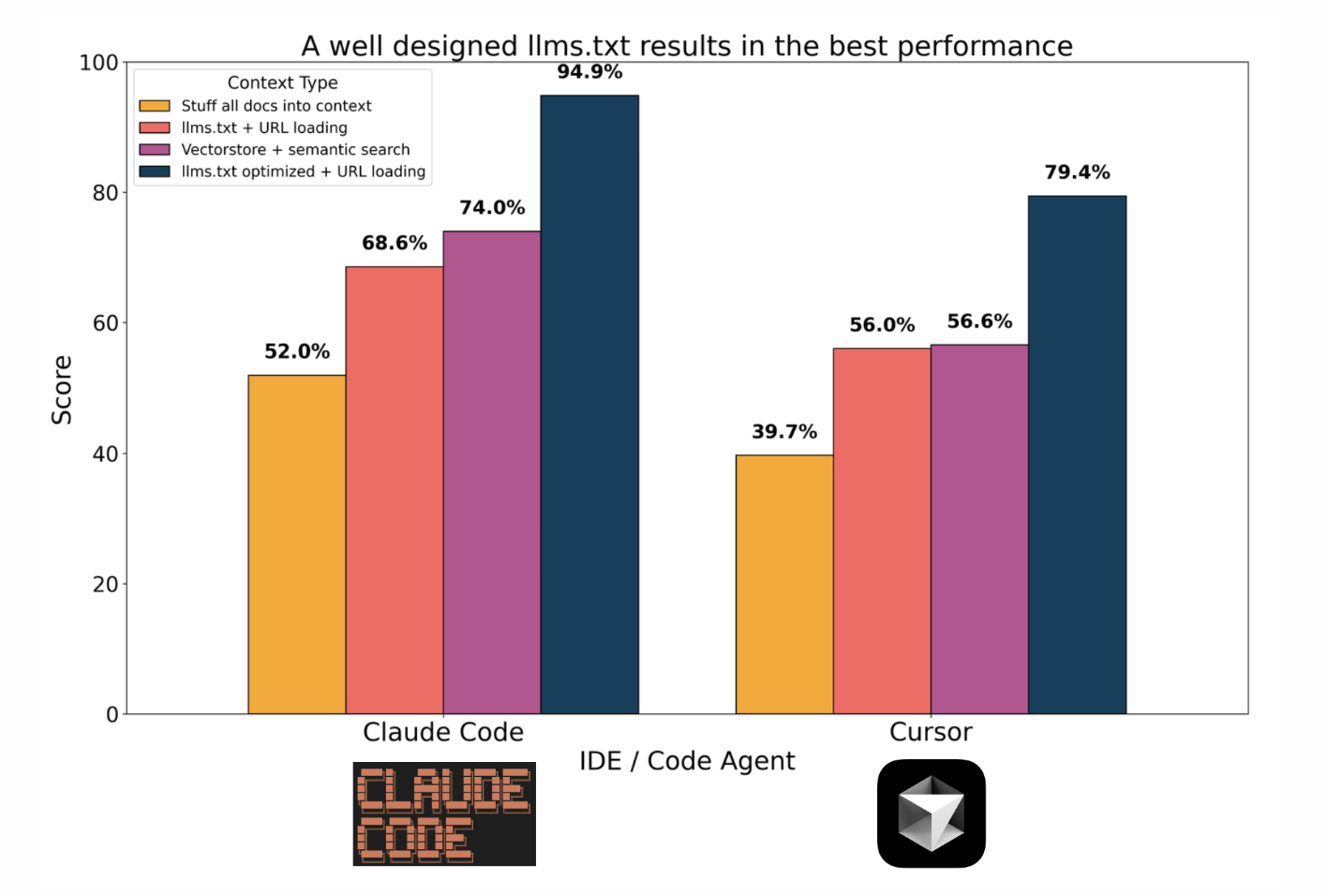
Benchmark comparison of retrieval methods from Lance Martin's blog post
In real-world tests on developer docs, practitioners have found that a well-crafted llms.txt (URLs + succinct descriptions) plus simple tool calls, such as grep, outperforms vector DB pipelines for various coding tasks. It’s not only more accurate, but also dramatically easier to maintain and update.
Why does this minimalist approach work so well?
- Codebases have explicit structure and intent. Each function, class, or module serves a clear purpose and lives in a predictable, structured place. When an agent understands the task, e.g., “find how this API handles authentication”, it can trace that logic directly through file names, imports, and docstrings, without needing fuzzy semantic matching.
- The LLM’s reasoning loop is the retrieval algorithm. Instead of outsourcing relevance to a vector search system, the model plans its own retrieval path, deciding what to open, read, and reference next, guided by its internal understanding of context and goals.
This is the essence of the new agentic retrieval paradigm: move retrieval intelligence into the model, keep external tools minimal, and represent the corpus in a way the LLM can navigate through reasoning rather than similarity. It’s about trusting and leveraging the model’s ability to reason, plan, and retrieve autonomously; not treating it as a passive consumer of externally retrieved chunks, but as an active agent capable of reasoning, retrieving, and deciding what to read next.
Can We Do the Same for Non-code Documents?
Yes, but “documents” aren’t code repos. Code has functions and directories; PDFs have structure: sections, subsections, figures, appendices. A simple list of URLs or code files isn’t enough here. What the model needs is a structured overview it can reason over.
Enter PageIndex — our approach to agentic indexing and retrieval for long documents: reports, filings, manuals, papers, textbooks, and more.
What is PageIndex?
PageIndex is an LLM-native, vectorless index that represents a document as a hierarchical tree, like a human-readable table of contents enriched with smart summaries. We place that index directly inside the LLM’s context window, enabling context-aware, reasoning-based retrieval where the model can:
- Inspect the tree to infer where the answer is likely to live (high-level reasoning).
- Drill down and request the specific page, section, or paragraph.
- Read only what’s needed, then answer, achieving precise retrieval with minimal context load.
No chunking or embeddings. No vector database. Just structure and context-aware reasoning.
Why it works
- Humans retrieve by structure. When humans read, we skim headings, then navigate to the relevant subsection. LLMs can do the same, if given a clear, navigable map of the document.
- LLM-native index and retrieval. The index is designed for the model to read and reason over, and retrieval is driven by reasoning rather than opaque embeddings similarity search. It’s like giving the model a compact “study guide” for a document.
- Agentic control. The model decides which branch of the index to open next, just like a developer agent decides which file to read.
Retrieval Patterns Comparison
Below is a side-by-side comparison of the retrieval patterns.
| Pattern | Mental model | What you maintain | Pros | Trade-offs |
|---|---|---|---|---|
| Vector DB RAG | Similarity search | Chunks, embeddings, and vector DB | Scales across huge corpora; mature tooling ecosystem | High complexity; costly indexing; debugging relevance is hard |
| llms.txt + tools (for code) | “Smart directory + grep” | A curated list of files with descriptions | Simple, fast to update; highly effective for code tasks | Needs high-quality descriptions; less suited for deep narrative structure |
| PageIndex (for documents) | “Reason over ToC tree for retrieval” | Hierarchical context tree with node summaries | Traceable, explainable, human-like retrieval; no embeddings or chunking | Requires generating/maintaining structure; context budget management (mitigated via tree search) |
Together, these patterns illustrate a broader transition: from similarity-centric retrieval to reasoning-driven retrieval, and from indexing for machines to indexing for LLMs.
How PageIndex Works in Practice
Connect PageIndex to LLMs or Agents (via MCP)
- Expose the index to the LLM or agent. PageIndex converts a document into a structured hierarchical tree, and exposes it to the model’s context window through the MCP server. This gives the model a navigable in-context index instead of pre-fetched static chunks.
- Enable interactive, agentic retrieval. The LLM can browse the index in real time: listing nodes, reading summaries, and opening sections on demand, turning retrieval into a reasoning-driven agentic process rather than a predefined pipeline.
- Provide context on demand. When answering a question, the model queries the index directly (e.g., open §2.1.3 or page 27) to load only the relevant context into its context window, delivering precision without token bloat.
By exposing PageIndex through MCP, LLMs or agents can interactively navigate documents, transforming retrieval from a static search pipeline into an active reasoning loop.
When to Choose PageIndex over Vectors
Pick PageIndex when:
- Your documents are long-form, structured — financial reports, legal docs, technical manuals, policies, medical files, and more.
- You need traceable, interpretable retrieval — the ability to see why the agent opened a specific section or page, and why a passage was retrieved, not just what was retrieved.
- You need context-relevant retrieval — retrieval driven by reasoning over document structure and context, not similarity matches on isolated chunks.
- You prefer lightweight infrastructure — no vector stores, no embedding pipelines, and minimal maintenance overhead.
Pick vector search when:
- You’re working across many loosely related documents with weak or inconsistent structure.
- Queries are fuzzy or exploratory, and broad semantic recall across diverse content matters more than fine-grained precision, e.g., in recommendation or discovery systems.
You can always combine both approaches to achieve a balance between scale and precision, getting the best of both worlds.
Practical Wins We’ve Observed
- Shorter, cleaner contexts. The agent retrieves only what it needs: reducing irrelevant context, minimizing hallucinations, and keeping answers firmly grounded in the source documents.
- Traceable and explainable reasoning for retrieval. Retrieval is driven by reasoning rather than similarity matching. Every result can be traced back to specific nodes, headings, and pages; the reasoning path used to retrieve the context is transparent and auditable, making it clear where the answer came from and why it was chosen.
- Proven benchmark performance. On FinanceBench, a widely used benchmark for financial QA, PageIndex-based retrieval achieved 98.7% accuracy, outperforming vector-based RAG pipelines and other industrial solutions in the market.
- Faster iteration cycles. Updating a heading, refining a node summary, or adjusting the hierarchy takes effect immediately, without costly re-embedding or index rebuilds.
- Human-readable debugging. You don’t debug embeddings or opaque similarity scores. You inspect the document structure, node summaries, and reasoning for retrieval to understand and correct retrieval behaviour.
- Model portability. Because the index is self-descriptive and structure-driven, you’re not locked into a specific embedding model or vector database.
What About Context Limits?
PageIndex is built to avoid context bloat by design:
- The top-level tree index is compact (think a page or two).
- The agent can perform tree-based search, reasoning down the hierarchy and opening only the branches and leaf nodes that are relevant.
- For very large documents, only the top k levels of the tree are loaded initially; deeper nodes are fetched on demand.
In short, PageIndex front-loads structure rather than full text, keeping the context lean while preserving access to the full document.
How This Relates to llms.txt
Shared spirit:
- Provide a compact, human-like guide the model can reason over.
- Let the LLM’s reasoning drive which resource to open next.
- Keep tooling simple, transparent, and adaptable.
Key difference:
- llms.txt is a flat directory of files, well suited for code repos.
- PageIndex is a hierarchical structure of document context, ideal for understanding and navigating complex documents.
Think of PageIndex as “llms.txt for documents”, but with a hierarchical structure that enables reasoning over structure and context, not just a flat list of entries.
The Bigger Picture
Retrieval has long lived outside the model: in databases, embeddings, and external pipelines.
PageIndex flips that paradigm. By placing the index directly inside the LLM’s context window, retrieval is no longer an external infra and becomes part of the model’s reasoning loop. Instead of relying on externally retrieved isolated chunks, the model can now navigate and reason through the document — reading its structure, choosing what to open, and pulling in only what is relevant, reasoning its way to the answer.
Claude Code proved that you can solve real tasks without a vector store, by letting the model handle retrieval directly. PageIndex brings the same simplicity and power to your documents and knowledge bases: reports, filings, papers, manuals, and more. If you’ve felt the pain of vibe similarity search or over-engineered RAG pipelines, there’s a simpler path: make the index something the model can read and reason over, and let the model handle retrieval via context-aware reasoning.
To learn more, see a detailed introduction to the PageIndex framework. You can also explore our GitHub repo for open-source code, and the cookbooks, tutorials, and blog for additional usage guides and examples. The PageIndex service is available as a ChatGPT-style chat platform, or can be integrated via MCP or API.